Empowering Scalable AI and Generative Innovation with Data Mesh Architecture




In today’s data-driven enterprises, data mesh architecture is emerging as a paradigm shift in how organizations manage analytical data at scale. Unlike traditional centralized data warehouses or data lakes, a data mesh decentralizes data management by aligning it with business domains and treating data as a product. This approach distributes data ownership to the teams closest to the data while maintaining overarching standards and governance. The motivation for data mesh arises from limitations in older architectures: monolithic data lakes and warehouses often struggle to keep pace with the proliferation of data sources, diverse use cases, and the need for agility [1] [6]. In contrast, a data mesh embraces a domain-oriented, self-serve design that can address these challenges. It is essentially an architectural and organizational blueprint that enables scalable, decentralized data management – analogous to how microservices revolutionized monolithic software systems [4]. By shifting from a single centralized platform to a federated network of domain data products, enterprises aim to achieve greater scalability, faster access to quality data, and more resilient data pipelines. This introduction outlines what a data mesh is and why it’s important, setting the stage for a deeper look at its principles, applications in AI (especially generative AI), comparisons with legacy architectures, and a real-world case study.
Principles of Data Mesh
A data mesh is built on four core principles [2] that together redefine both the technical architecture and the organizational model for data:
- Domain Ownership – Decentralize data responsibilities by giving each business domain (such as marketing, sales, or operations) end-to-end ownership of “their” data. Rather than a central data team handling all enterprise data, domain teams become accountable for providing, transforming, and serving the data they know best. This means the people most familiar with the data govern its quality and evolution. Domains are empowered to ingest and curate their data, and are responsible for ensuring it’s accurate, well-documented, and usable by others [4]. In practice, this principle mirrors the idea of microservices in software: each domain team manages its data independently but adheres to common standards, enabling parallel development and scalability.
- Data as a Product – Treat datasets as discrete products that are created to serve consumers (be it other teams, data scientists, or applications) with a clear value proposition. This principle shifts the mindset from seeing data as exhaust of operations to viewing it as a first-class product with its own life cycle. Domain teams act as data product owners, curating their datasets for usability, quality, and reliability [4]. Each data product comes with metadata, documentation, and APIs or interfaces, so it’s easily discoverable and consumable. For example, an e-commerce domain might offer a “Customer Purchases” data product that is consistently updated, well-described, and readily available for analytics or machine learning, much like a well-maintained service or API in a product catalog.
- Self-Serve Data Platform – Provide a self-serve data infrastructure as a platform to support domain teams in publishing and consuming data products without needing to build pipelines and tooling from scratch. A central data platform team (or cross-functional platform) offers standardized infrastructure – storage, processing engines, pipelines, data catalogs, security, etc. – as a managed service for all domains [4]. This platform abstracts away low-level complexity (such as provisioning cluster resources or managing schema transformations) so that domain teams can focus on data logic and quality. In essence, it’s a unified tooling layer that makes it easy to create, share, and use data across the mesh, analogous to an internal “data OS.” The self-serve platform ensures interoperability between data products, providing capabilities like common data formats, lineage tracking, and monitoring, which are crucial for a distributed data environment.
- Federated Computational Governance – Implement a federated approach to data governance that strikes a balance between decentralization and central oversight. In a data mesh, governance is not a top-down afterthought but a built-in, automated aspect of the platform (“computational” governance). A cross-domain governance body defines global policies – e.g. for data security, privacy, quality standards, and interoperability – and these policies are enforced through code and shared protocols across all domains [4]. Each domain agrees to abide by common standards (for instance, using standard data definitions or access controls), ensuring that despite decentralization, the enterprise data landscape remains interoperable and compliant. This federated model means domain teams have autonomy but within guardrails: governance is a shared responsibility.
To visualize these principles, consider an architecture where each domain has its own dedicated data repository (data product) and a central “mesh” catalog or platform connects them to data consumers.
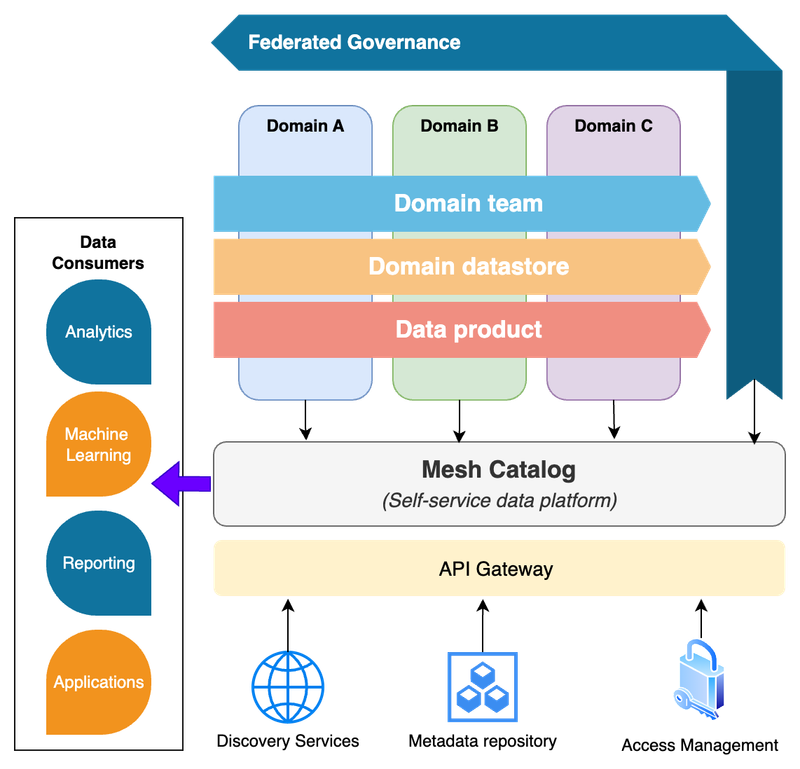
Figure 2- Illustration of a data mesh logical architecture
Each colored “domain” in the figure represents a domain-owned analytical datastore (with its own data and schema catalog), and the mesh catalog in the center allows any authorized consumer to discover and query data across domains without those datasets all living in one physical repository. This design embodies domain-oriented ownership (each domain has its own data store), data-as-product thinking (each domain’s data is offered as a product in the mesh), a self-service platform (the mesh catalog and underlying tools that connect producers and consumers), and federated governance (common standards enabling the red, yellow, and blue domain data to integrate and comply with global policies).
Applications in AI and Generative AI
One of the compelling motivations for data mesh is its ability to support scalable AI and ML initiatives. Modern AI, especially generative AI, thrives on large volumes of high-quality, wide-ranging data. Data mesh architecture directly contributes to this by ensuring data is accessible,trustworthy, and up-to-date across an organization’s domains, which in turn feeds AI models with better inputs. There are several ways data mesh enables AI development and operations:
- Scalable Data Pipelines for AI: In a data mesh, each domain continuously produces well-defined data products that can serve as reliable sources for model training and analytics. This decentralized pipeline structure prevents the central data engineering bottlenecks that often plague AI projects. Data scientists no longer wait in a long queue for a single data team to provision or prepare data; instead, they can pull from domain-curated datasets on the self-serve platform as needed. This has a direct impact on AI scalability – organizations can develop multiple models in parallel, leveraging data from different domains, without overwhelming a central pipeline. A Microsoft analysis notes that data mesh’s distributed ownership leads to improved data quality and governance, accelerating time-to-value for analytics and AI use cases [3].
- High-Quality, Context-Rich Data for ML: Because domain teams are responsible for their data and treat it as a product, the data feeding into AI models tends to be more context-rich and clean. Domain experts understand the nuances of the data (e.g., how an e-commerce domain defines “active customer” or how a manufacturing domain logs sensor readings) and ensure those datasets are properly documented and vetted. This context and quality are crucial for AI. Surveys have long shown that data scientists spend roughly 60–80% of their time on data preparation (cleaning and organizing data), leaving only 20% for actual modeling [8]. By delivering cleaner, analysis-ready data through a mesh, organizations can flip this ratio – data scientists can invest more time in developing models rather than wrangling data. Moreover, since each data product in the mesh is “trustworthy and truthful” by design (to use Dehghani’s criteria [1]), AI engineers can have greater confidence in the consistency and lineage of features they use for training. This reduces duplicated effort in feature engineering and helps avoid situations where different teams unknowingly clean or transform the same data in different ways.
- Cross-Domain Data for Advanced AI: Generative AI models (like large language models or other foundation models) often benefit from diverse data coming from multiple domains. Data mesh makes cross-domain data integration more fluid, because data products are inherently shareable and built with interoperability in mind. Instead of pulling data into one central lake for aggregation (which can be slow and complex for large-scale AI), the mesh approach allows AI systems to query data in place across domains or to subscribe to domain data as it’s published. For instance, a generative AI application that creates personalized reports might draw on product data from one domain, customer feedback from another, and knowledge base articles from a third – all accessible through the mesh’s platform. This federated access pattern supports AI without requiring all data to be copied centrally, thus enabling real-time or near-real-time data availability for AI consumption. It also inherently preserves data provenance, which is valuable when tuning or troubleshooting models (you always know which domain product a given training data point came from).
- Governance and Responsible AI: Generative AI increases risks around data privacy, security, and ethical usage. Data mesh's federated governance provides a structured approach to enforce policies across all AI-utilized data. Global rules can ensure sensitive information (PII, health data) meets compliance requirements before model training, regardless of source domain. The mesh's "built-in" governance enables automated checks: preventing exposure of low-quality training data and ensuring lineage tracking for audit purposes—critical for generative AI's vast datasets where understanding inputs helps address bias concerns. Industry practitioners emphasize that a strong data foundation is essential for effective generative AI implementation. Guardant Health exemplifies this; their data mesh established a robust platform that "is helping the company harness generative AI" with proper security and domain grounding [9]. In practice, their domain-organized genomic data products can integrate with services like Amazon Bedrock to build advanced AI models while maintaining governance standards. The federated governance model thus enables AI innovation while ensuring enterprise and regulatory compliance.
- Accelerating AI Experimentation: Finally, data mesh supports a culture of innovation in AI. Since domain teams can publish new data products and make them immediately available enterprise-wide, data scientists and ML engineers can rapidly discover new data and combine it in novel ways. This reduces friction in spinning up experiments – for example, an NLP team might find a rich trove of customer interaction logs in the support domain’s data product and use it to fine-tune a language model for customer sentiment analysis, without having to negotiate a long integration project. The self-serve platform often includes data catalogs and marketplaces which make finding and understanding data easier (much like an app store for data), further speeding up AI development cycles. The outcome is that organizations with a data mesh can respond faster to new AI opportunities, scaling successful prototypes to production because the underlying data infrastructure is already in place to support dynamic, cross-domain data needs.
Data mesh provides the data backbone for AI in large organizations: it ensures that high-quality data is readily available and well-governed, which is foundational for building reliable AI and generative AI systems at scale. Early adopters have noted improved agility in their AI projects once mesh principles are in place, as the heavy lifting of data provisioning and cleanup is reduced. However, it’s worth noting that implementing a data mesh for AI also requires rethinking team structures (e.g. embedding data engineers and scientists in domain teams) and investing in platform capabilities like feature stores and model governance, as new practices such as the emerging concept of a “feature mesh” (domain-driven feature engineering) build upon the data mesh to further streamline AI development [3]. With the right approach, a data mesh can become a catalyst for an organization’s AI ambitions, providing a scalable data supply chain for the era of generative AI.
Comparative Analysis: Data Mesh vs. Traditional Architectures
To appreciate the strengths and weaknesses of data mesh, it’s important to compare it with traditional data architectures like data warehouses and data lakes, which have been the backbone of analytics for decades. Each approach has its merits and limitations:
- Data Warehouse (Centralized BI): Data warehouses serve as centralized repositories for structured, integrated data. They enforce a strict schema-on-write process and are typically managed by specialized data teams. This centralized model provides a single source of truth and optimized performance for analytics. However, as organizations expand, warehouses often become bottlenecks. The rigidity of ETL processes means that adapting to new data types or business requirements can take weeks. Additionally, a small, centralized team may struggle with scaling and meeting diverse data needs, leading to accumulated technical debt [6]. In short, warehouses excel at consistency and quality for predefined use cases, but they are less flexible in the face of rapid growth and diversification of data needs.
- Data Lake (Centralized Big Data): Data lakes emerged to handle large volumes of raw data, including unstructured formats, by employing schema-on-read. They offer high scalability and the ability to store diverse data types, making them suitable for advanced analytics and machine learning workloads. Nevertheless, without stringent governance, data lakes can devolve into “data swamps”—massive, disorganized pools of data that are difficult to navigate and trust. The centralized ingestion process still often relies on a single team, which may be overwhelmed by the breadth of tasks required
- Data Mesh (Distributed Domain Data): Data mesh combines warehouse and lake strengths while addressing their limitations. It decentralizes data ownership into domain-specific products where teams independently manage their data pipelines and quality. A central self-serve platform and federated governance ensure consistency and interoperability across domains. This distributed approach enhances agility and scalability, enabling faster adaptation to changing requirements. However, implementation challenges exist. Success requires a mature data culture and governance—Gartner's research found that as of 2021, only about 18% of organizations have sufficient data governance maturity to successfully adopt a data mesh approach [10]. Without this foundation, domains risk becoming disconnected silos. Additionally, significant investment is needed in the self-serve platform infrastructure (cataloging, pipeline automation, access control across distributed teams), which can be complex to build and maintain. Engineering the mesh for efficient cross-domain queries also remains challenging.
In essence, data warehouses excel at delivering consistent, high-quality data for specific use cases but often lack the flexibility needed in fast-growing environments. Data lakes offer scalability and accommodate raw, diverse data but can become disorganized without proper controls. Data mesh, by contrast, emphasizes domain ownership and treats data as a product, enabling decentralized, agile, and scalable data management. While it presents challenges in implementation and governance, data mesh is well-suited for organizations seeking rapid insight across varied data sources and those aiming to harness modern AI and generative technologies.
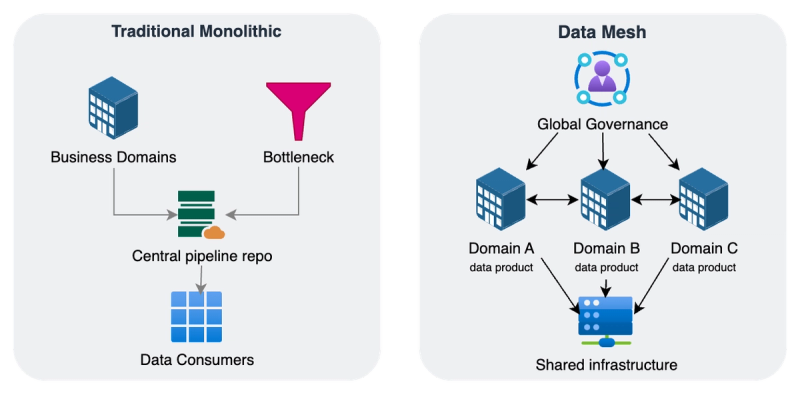
Figure 2 – A Conceptual comparison of centralized vs. domain-driven data architecture
The figure above reflects the shift from a single data lake to a distributed mesh of data products. Domain teams – represented by the colored bubbles and icons of people – own and serve their data, while a common platform (bottom) provides storage, pipelines, catalog, and access control. The global governance umbrella (top) ensures all domains adhere to shared standards, enabling the whole network to function coherently.
Conclusion
Implementing a data mesh architecture represents a significant evolution in enterprise data strategy. It shifts the focus from centralized technology to a federation of data products managed by cross-functional teams, all aligned under shared governance. As we’ve discussed, this approach is particularly well-suited to organizations aiming to scale up AI and generative AI applications – it provides the data volume, variety, and veracity that modern AI demands, without the bottlenecks of older architectures. Key insights include the importance of treating data as a product (which elevates data quality and usability), the need for robust self-service infrastructure (which is the enabler for domain teams to operate autonomously), and the critical role of governance (the glue that holds the decentralized system together and ensures trust). Data mesh is not a silver bullet; it comes with challenges in implementation. Organizations must cultivate a data-centric culture and invest in talent and platforms. As one industry expert put it, adopting data mesh and a product mindset requires “reassessing capabilities, undergoing a cultural shift, developing talent, and…commitment to cultural and technical change” [11]. In other words, success with data mesh is as much about people and process as it is about technology.
Looking ahead, we can expect the data mesh concept to further mature. Future trends may include integration with data fabric concepts (to automate some of the integration work and perhaps reduce the complexity for organizations not ready for full mesh), more tooling and SaaS offerings that provide out-of-the-box self-serve platforms for mesh (accelerating adoption), and the rise of data product marketplaces within companies. As data privacy and AI ethics take center stage, federated governance models will likely become standard, influenced by data mesh principles, to ensure compliance across distributed data environments. Moreover, the experiences of early adopters will produce best practices—such as how to define domain boundaries, how to measure the success of data products, and how to gradually refactor a legacy data lake into a mesh.
References:
[1] Dehghani, Zhamak. How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh. Martin Fowler (May 2019). https://martinfowler.com/articles/data-monolith-to-mesh.html
[2] Dehghani, Zhamak. “Data Mesh Principles and Logical Architecture.” martinfowler.com (Dec 2020). https://martinfowler.com/articles/data-mesh-principles.html
[3] Microsoft Azure Architecture Center. “Operationalize data mesh for AI/ML – domain driven feature engineering.” (Nov 2024). https://learn.microsoft.com/en-us/azure/cloud-adoption-framework/scenarios/cloud-scale-analytics/architectures/operationalize-data-mesh-for-ai-ml
[4] Booz Allen Hamilton. “Enabling AI Through the Data Mesh.” boozallen.com (2023). https://www.boozallen.com/insights/defense/defense-leader-perspectives/enabling-ai-through-the-data-mesh.html
[5] Hazen, Sam. “Data Mesh vs. Data Lake: Key Differences & Use Cases for 2025.” Atlan Blog (Dec 2024). https://atlan.com/data-mesh-vs-data-lake
[6] Monte Carlo Data. “What Is A Data Mesh — And How Not To Mesh It Up.” montecarlodata.com (2022). https://www.montecarlodata.com/blog-what-is-a-data-mesh-and-how-not-to-mesh-it-up
[7] AWS Big Data “How JPMorgan Chase built a data mesh architecture to drive significant value to enhance their enterprise data platform” (2021). https://aws.amazon.com/blogs/big-data/how-jpmorgan-chase-built-a-data-mesh-architecture-to-drive-significant-value-to-enhance-their-enterprise-data-platform
[8] Dataversity. “Survey Shows Data Scientists Spend Most of Their Time Cleaning Data.” dataversity.net (2016). https://www.dataversity.net/survey-shows-data-scientists-spend-time-cleaning-data
[9] AWS Case Study. “Guardant Health’s Data Platform on AWS Helps It Conquer Cancer with Generative AI.” aws.amazon.com (2023). https://aws.amazon.com/solutions/case-studies/guardant-health-case-study/
[10] Atlan. “Gartner on Data Mesh: Future of Data Architecture in 2025?” atlan.com (2023). https://atlan.com/gartner-data-mesh/
[11] Fractal Analytics. “From Monolithic Structures to Agile Platforms: How Cloud and GenAI are Shaping Data Strategies.” fractal.ai (2023). https://fractal.ai/data-management-with-data-mesh-architecture-and-genai/
About the author
Kiran is a Principal Solutions Architect at Amazon Web Services (AWS) who leverages over 17 years of experience in cloud computing and machine learning to drive sustainable, AI-powered innovations. Known for his expertise in migration & modernization, data & analytics, AI and ML, security, and other cutting-edge technologies. In his current capacity, Kiran works closely with AWS's Global Strategic SI (System Integrator) partners. He works diligently to create and implement successful cloud strategies that allow these partners to get the full benefits of cloud technology. Kiran holds an MBA in Finance and a Bachelor of Technology degree in Electrical & Electronics. He also holds several AWS Certifications. Kiran is a member of INFORMS, a Senior IEEE member and a fellow at IETE (India). Connect with Kiran Randhi on LinkedIn.
At The Edge Review, we believe that groundbreaking ideas deserve a global platform. Through our multidisciplinary trade publication and journal, our mission is to amplify the voices of exceptional professionals and researchers, creating pathways for recognition and impact in an increasingly connected world.
Member
%20--%3e%3c!DOCTYPE%20svg%20PUBLIC%20'-//W3C//DTD%20SVG%201.1//EN'%20'http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd'%3e%3csvg%20version='1.1'%20id='Layer_1'%20xmlns='http://www.w3.org/2000/svg'%20xmlns:xlink='http://www.w3.org/1999/xlink'%20x='0px'%20y='0px'%20viewBox='0%200%20200%2067.9'%20style='enable-background:new%200%200%20200%2067.9;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill:%234F5858;}%20.st1{fill:%233EB1C8;}%20.st2{fill:%23D8D2C4;}%20.st3{fill:%23FFC72C;}%20.st4{fill:%23EF3340;}%20%3c/style%3e%3cg%3e%3cg%3e%3cg%3e%3cg%3e%3cpath%20class='st0'%20d='M76.1,37.5c-0.4-2.6-2.9-4.6-5.8-4.6c-5.2,0-7.2,4.4-7.2,9.1c0,4.4,2,8.9,7.2,8.9c3.6,0,5.6-2.4,6-5.9H82%20c-0.6,6.6-5.1,10.8-11.6,10.8c-8.2,0-13-6.1-13-13.7c0-7.9,4.8-14,13-14c5.8,0,10.7,3.4,11.4,9.5H76.1z'/%3e%3cpath%20class='st0'%20d='M84,35.9h5v3.6h0.1c1-2.4,3.6-4.1,6.1-4.1c0.4,0,0.8,0.1,1.1,0.2v4.9c-0.5-0.1-1.3-0.2-1.9-0.2%20c-3.9,0-5.2,2.8-5.2,6.1v8.6H84V35.9z'/%3e%3cpath%20class='st0'%20d='M106.4,35.4c6,0,9.9,4,9.9,10.1c0,6.1-3.9,10.1-9.9,10.1c-6,0-9.9-4-9.9-10.1%20C96.5,39.4,100.4,35.4,106.4,35.4z%20M106.4,51.6c3.6,0,4.7-3.1,4.7-6.1c0-3.1-1.1-6.1-4.7-6.1c-3.6,0-4.6,3.1-4.6,6.1%20C101.8,48.6,102.8,51.6,106.4,51.6z'/%3e%3cpath%20class='st0'%20d='M122.4,48.9c0,2.3,2,3.2,4,3.2c1.5,0,3.4-0.6,3.4-2.4c0-1.6-2.2-2.1-6-3c-3-0.7-6.1-1.7-6.1-5.1%20c0-4.9,4.2-6.1,8.3-6.1c4.2,0,8,1.4,8.4,6.1h-5c-0.1-2-1.7-2.6-3.6-2.6c-1.2,0-2.9,0.2-2.9,1.8c0,1.9,3,2.1,6,2.9%20c3.1,0.7,6.1,1.8,6.1,5.4c0,5-4.4,6.7-8.7,6.7c-4.4,0-8.8-1.7-9-6.7H122.4z'/%3e%3cpath%20class='st0'%20d='M141.6,48.9c0,2.3,2,3.2,4,3.2c1.5,0,3.4-0.6,3.4-2.4c0-1.6-2.2-2.1-6-3c-3-0.7-6.1-1.7-6.1-5.1%20c0-4.9,4.2-6.1,8.3-6.1c4.2,0,8,1.4,8.4,6.1h-5c-0.1-2-1.7-2.6-3.6-2.6c-1.2,0-2.9,0.2-2.9,1.8c0,1.9,3,2.1,6,2.9%20c3.1,0.7,6.1,1.8,6.1,5.4c0,5-4.4,6.7-8.7,6.7c-4.4,0-8.8-1.7-9-6.7H141.6z'/%3e%3cpath%20class='st0'%20d='M156.1,35.9h5v3.6h0.1c1-2.4,3.6-4.1,6.1-4.1c0.4,0,0.8,0.1,1.1,0.2v4.9c-0.5-0.1-1.3-0.2-1.9-0.2%20c-3.9,0-5.2,2.8-5.2,6.1v8.6h-5.3V35.9z'/%3e%3cpath%20class='st0'%20d='M174.2,46.8c0.1,3.3,1.8,4.9,4.7,4.9c2.1,0,3.8-1.3,4.1-2.5h4.6c-1.5,4.5-4.6,6.4-9,6.4%20c-6,0-9.8-4.1-9.8-10.1c0-5.7,4-10.1,9.8-10.1c6.5,0,9.7,5.5,9.3,11.4H174.2z%20M182.7,43.5c-0.5-2.7-1.6-4.1-4.2-4.1%20c-3.3,0-4.3,2.6-4.4,4.1H182.7z'/%3e%3cpath%20class='st0'%20d='M190.9,39.5h-3.1v-3.5h3.1v-1.5c0-3.4,2.1-5.8,6.4-5.8c0.9,0,1.9,0.1,2.8,0.1v3.9c-0.6-0.1-1.3-0.1-1.9-0.1%20c-1.4,0-2,0.6-2,2.2v1.1h3.6v3.5h-3.6v15.6h-5.3V39.5z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cpolygon%20class='st1'%20points='0,67.9%200,47.4%2016.8,41.9%2046.6,52.1%20'/%3e%3cpolygon%20class='st2'%20points='29.8,26.1%200,36.4%2016.8,41.9%2046.6,31.7%20'/%3e%3cpolygon%20class='st0'%20points='16.8,41.9%2046.6,31.7%2046.6,52.1%20'/%3e%3cpolygon%20class='st3'%20points='46.6,0.2%2046.6,20.6%2029.8,26.1%200,15.9%20'/%3e%3cpolygon%20class='st4'%20points='29.8,26.1%200,36.4%200,15.9%20'/%3e%3c/svg%3e)
Important Links
Contact Info
info@theedgereview.org
Address:
14781 Pomerado Rd #370, Poway, CA 92064