Enhancing Reasoning in LLMs through Contrastive Estimation and Representation Engineering



Large Language Models (LLMs) have made tremendous strides, yet true reasoning remains a frontier challenge. These models often struggle with complex multi-step reasoning tasks, especially those requiring logic or intermediate calculations. Unlike straightforward queries (e.g., “What’s the capital of France?”), reasoning questions demand a chain of logical steps – for example, solving a math word problem or debugging code – which pushes LLMs beyond simple pattern matching. The critical value of advancing reasoning in large language models cannot be emphasized enough. Stronger reasoning abilities empower AI to solve sophisticated challenges across science, engineering, and daily decision-making, moving closer to reliable AI assistants and autonomous problem solvers. Leading research initiatives underscore this priority. OpenAI’s and Deepseek’s latest models explicitly spend “more time thinking through problems before they respond,” yielding significant advancements on hard tasks in math, coding, and science [3]. In short, enhanced reasoning is key to unlocking a new level of AI capability and trustworthiness in real-world applications.
Two promising research directions are emerging to meet this challenge: token-level contrastive estimation and representation engineering. The former zooms in on the fine-grained decisions an LLM makes – literally at the token level – to pinpoint where its reasoning goes astray. The latter takes a top-down view, manipulating and interpreting the model’s internal representations (its “thought vectors”) to guide reasoning and align behavior. This article explores how these approaches work, and how both industry leaders and open-source communities are pushing the state of the art.
Token-Level Contrastive Estimation
One line of research attacks the reasoning problem at the level of individual tokens – the words or symbols an LLM generates step by step in its chain of thought. Modern LLMs tackle reasoning by generating sequences of tokens that form intermediate reasoning steps, often described as reasoning trajectories or a “chain-of-thought.” Each token can influence the subsequent direction of the solution. Recent work has revealed that some tokens have outsized influence: altering a single critical word can flip a solution from wrong to right. These pivotal tokens are dubbed “critical tokens.” Identifying and handling them is the focus of token-level contrastive estimation, which has proven surprisingly effective in boosting reasoning accuracy.
Researchers first noticed that forcing an LLM to avoid certain tokens can dramatically improve its reasoning outcomes. Lin et al. (2024) formalized this in Critical Tokens Matter, using mathematical problem solving as a testbed. They found that when an LLM’s chain-of-thought includes a critical token associated with a faulty reasoning pattern, the model often reaches an incorrect conclusion [1][6]. If the model is instead made to generate an alternative token at that step, it is far more likely to arrive at the correct answer. In other words, these tokens act like tipping points in the reasoning process. A tangible example is the word “owed.” In one experiment, an LLM solving a finance word problem kept using “owed” in its reasoning and consistently produced the wrong answer. Simply rephrasing the problem to use “paid” in place of “owed” led the model to a correct solution. The figure below illustrates this effect: the token "owed" steers the reasoning down a wrong path, whereas "paid" points it in the right direction, yielding a correct answer.
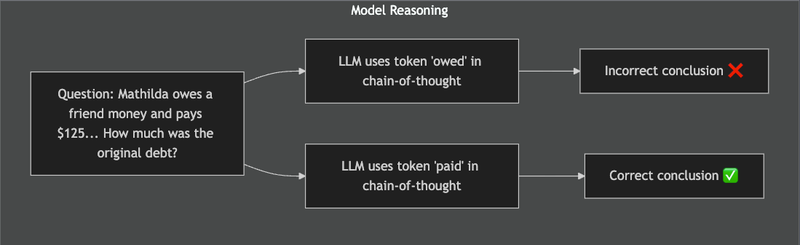
Figure: A single critical token can derail or save an LLM’s reasoning. In this example, using the word “owed” in the reasoning process leads to the wrong answer, whereas using “paid” yields the correct result.
To systematically harness this insight, Lin et al. introduced a training framework called contrastive Direct Preference Optimization (cDPO). The idea behind cDPO is to automatically discover which tokens are critical and then teach the model to avoid the bad ones. How does it work? In essence, the researchers train two versions of the LLM on the same task: one model (the “positive” model) learns from correct reasoning examples, and another (the “negative” model) learns from incorrect reasoning examples. During analysis, each model generates solutions and the likelihood of each token in those solutions is compared between the two. Tokens deemed likely by the positive model but not by the negative model—or the other way around—are flagged as critical tokens – they have a large contrast in probability, indicating a strong impact on correctness. For instance, if the correct-trained model strongly favors the token “divide” where the incorrect-trained model favors “multiply,” that token choice is likely critical to solving the problem correctly.
Once identified, these critical tokens are used to guide the main model’s training. The cDPO method extends the usual preference optimization (a technique related to reinforcement learning used in alignment) to the token level. Instead of just giving the model a reward for a correct final answer, cDPO gives token-level rewards or penalties – essentially telling the model “during your reasoning, avoid token X (and prefer Y) in this context.” Over time, the model internalizes these preferences, steering its chain-of-thought away from known pitfalls. This fine-grained alignment significantly improves performance on reasoning benchmarks. Empirical results on challenging math datasets like GSM8K (a grade-school math word problem set) and MATH500 showed cDPO outperforms previous methods, boosting accuracy by several percentage points over the best baseline. In fact, on GSM8K and MATH500, a cDPO-enhanced LLM (applied to models like LLaMA-3 70B and DeepSeek-Math 7B) achieved new state-of-the-art results, indicating fewer logical errors in its solutions. While gains of a few percentage points might sound modest, in these difficult benchmarks even small improvements are hard-won – and they translate to many more problems solved correctly. Moreover, this token-level focus offers interpretable insights: it highlights which words confuse the model, giving human developers actionable clues to improve prompts or training data. Overall, token-level contrastive estimation has emerged as a powerful tool to diagnose and fix reasoning flaws in LLMs by targeting the very building blocks of their thinking process.
Representation Engineering
Where token-level methods zoom in on local decisions, representation engineering takes a global, top-down perspective on LLM reasoning. The core idea of representation engineering (RepE) is to leverage the model’s internal representations – the numerical vectors inside the neural network – as levers to interpret and influence reasoning. Instead of treating the model as a black box that maps input tokens to output tokens, RepE treats it as a rich cognitive system with hidden states that can be read or modified to guide behavior. This approach draws inspiration from cognitive neuroscience: just as brain imaging might reveal patterns corresponding to a thought, probing a network’s hidden layers can reveal whether it’s thinking about, say, a sub-goal or a factual recall. More importantly, by manipulating those internal representations, we can potentially steer the model’s reasoning process from the inside out.
A recent study by Zou et al. (2023) formally introduced representation engineering as a transparency and control technique [2]. They argue that focusing on neurons or individual weights is less productive than focusing on higher-level representations – vectors in hidden layers that encode meaningful concepts or states. By analyzing and editing these representations, researchers demonstrated control over complex model behaviors related to truthfulness, harmlessness, and decision-making. For example, they could measure how much a certain “honesty” representation was present in the model’s state to detect if the model was likely to hallucinate or lie. They also showed that adding a certain vector to the internal state could make the model more cautious or power-averse, potentially mitigating power-seeking tendencies in AI. These results illustrate how RepE can directly address safety-relevant aspects of reasoning by operating at the level of the model’s thoughts, not just its words.
One of the key techniques in representation engineering is the use of control vectors. A control vector is essentially a learned offset that can be added to the model’s hidden activations to consistently evoke a certain property or style in the output. For instance, imagine we analyze the difference in internal representation when a model answers questions normally versus when it is instructed to be “self-reflective.” If we compute a vector that captures that difference, we can then add that vector to the model during inference to make it behave as if it were in self-reflective mode, without changing the prompt or fine-tuning the weights. This is done for every layer of the network (hence a control “vector” is a set of offsets across layers) to subtly bias the ongoing computation. Vogt Goehring (2024) demonstrated this with a series of creative experiments on the open-source Mistral-7B model. By crafting control vectors for whimsical concepts like “lazy vs. diligent,” or “extremely self-aware,” he was able to make the same Mistral-7B model respond in dramatically different tones and behaviors, all through internal representation tweaks. Notably, this was achieved without any additional training or prompt engineering – the prompt to the model remained constant, but the injected vector altered the model’s chain-of-thought to produce novel behavior. Such control shows promise for reasoning too: one could imagine a control vector for “logical step-by-step reasoning” that makes the model follow a rigorous deductive process, or a vector for “skepticism” that makes it double-check facts, thereby reducing reasoning errors.
Another aspect of RepE is representation reading, which is about interpreting the model’s hidden state. Instead of adding a vector, here we extract a vector and analyze it. For example, one can train a simple probe (like a linear classifier) on the hidden state to detect if the model is currently thinking about a certain sub-problem or if it has memorized a fact. In a large transformer with dozens of layers, we might find that at layer 20 there’s a direction in the vector space that corresponds to “the user’s intent is a math problem” or “the model is about to carry out addition.” By reading this in real time, we gain transparency into the reasoning trajectory: we can literally watch the model think, in a rough sense. This could help diagnose why a model made a reasoning mistake – e.g., perhaps it never internally represented an important constraint of the problem. Such insights are valuable for debugging and improving models.
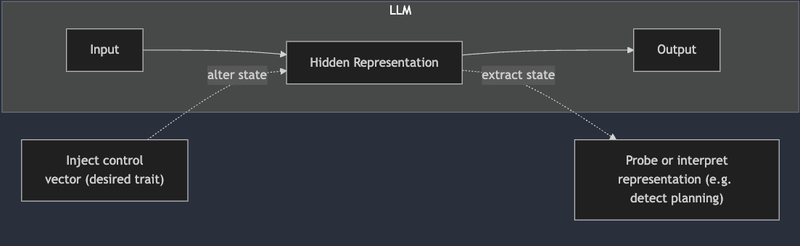
Figure: A simplified view of representation engineering. By reading the hidden representation of an LLM, we can interpret high-level attributes of its current “thought” (dashed arrow up). By injecting a specially crafted control vector into the hidden state, we can modify the LLM’s behavior or reasoning style on-the-fly (dashed arrow down), without changing the input or retraining the model.
In practical terms, representation engineering opens up new ways to fine-tune and align LLM reasoning without retraining from scratch. Instead of collecting thousands of examples to fine-tune a model to be better at planning, one could derive a control vector that, when applied, instantly improves the model’s planning behavior. This approach is still in its early stages, but it has already shown success on smaller models like Mistral-7B and GPT-2 variants, and there is active research into applying it at scale. The ability to manipulate internal representations also dovetails with token-level methods: for instance, if we know a certain critical token is problematic, representation engineering might allow us to adjust the model’s latent state right before it would generate that token, nudging it toward a better token instead. Both methods aim to inject more reasoning competence and control into LLMs – one from the outside in (by supervising tokens) and the other from the inside out (by editing thoughts).
Industry and Open-Source Efforts
Advancements in LLM reasoning are being driven by a mix of industry heavyweights and open-source initiatives, often in collaboration. Here we highlight key contributions from major players and the benchmarks guiding progress:
- OpenAI (Reasoning-Optimized Models) – OpenAI has explicitly prioritized reasoning with its GPT-4 and subsequent o1 model series. The OpenAI o1 models are a new class of LLMs “designed to spend more time thinking” and use chain-of-thought style training [3]. Through reinforcement learning and special training curricula, o1 models learn to refine their thinking process, try different strategies, and even recognize mistakes before finalizing an answer. The impact is dramatic: in one internal evaluation, an early GPT-4 model (GPT-4o) solved only 13% of problems on a qualifying math Olympiad exam, whereas a reasoning-optimized model solved 83%. Similarly, on coding tasks (simulated via Codeforces competitions), the reasoning-tuned model reached the 89th percentile. More recently, OpenAI introduced the o3 family of models, which further refine the reasoning process with enhanced multi-step planning and improved token-level calibration. Early reports indicate that the o3 models achieve even higher performance on complex reasoning benchmarks, while maintaining safety standards. These models demonstrate that with appropriate training, an LLM can drastically outperform even its strong predecessors on complex reasoning, albeit with some trade-offs in speed. OpenAI’s research also emphasizes safe reasoning – teaching the model to apply ethical and factual rules during its chain-of-thought, so it doesn’t just reason well, but also stays within guidelines.
- Anthropic (Claude and Constitutional AI) – Anthropic’s Claude models likewise focus on transparent, controllable reasoning. Claude 2 introduced Constitutional AI [4] to align the model’s reasoning with human values, and in late 2024 Anthropic unveiled Claude 3.7 “Sonnet,” described as a hybrid reasoning model. It offers an “extended thinking” mode where Claude will explicitly take more internal steps (a longer chain-of-thought) before producing a final answer. This mode lets users balance speed versus depth: enabling extended thinking makes Claude slower and more expensive per query, but often yields more detailed and accurate solutions on hard problems. In effect, Anthropic gives end-users a dial to turn the reasoning level up or down as needed. Under the hood, Claude’s chain-of-thought can be made partially visible to developers (for debugging) and is used in alignment research to ensure the model’s reasoning remains faithful to its answers (avoiding situations where the model’s stated reasoning diverges from its actual decision process). These efforts by Anthropic highlight the push for not only smarter, but more interpretable reasoning in large models.
- Google DeepMind (Gemini and “Flash” Reasoning) – Google’s DeepMind unit has blended its expertise from game-playing AI (like AlphaGo) with LLM development to produce the Gemini model series. Announced in late 2023 and iteratively improved, Gemini is intended to be multimodal and agentic, with strong built-in reasoning and planning abilities. In early 2025, Google introduced Gemini 2.0 Flash [9] – an experimental reasoning mode for the Gemini model available through Google’s AI Studio. Gemini 2.0 Flash is designed to handle complex tasks in programming, math, and even physics by breaking down prompts into smaller sub-tasks and reasoning through them step by step, similar to chain-of-thought. This approach echoes the ideas in OpenAI’s o1 and Anthropic’s Claude: the model internally generates a “thinking process” that it can optionally expose. The trade-off, as expected, is speed – the Flash Thinking mode requires longer processing time to produce an answer, as the model is effectively doing more computation per query. Jeff Dean of Google DeepMind noted that this kind of structured reasoning is a work in progress, and while it can greatly improve accuracy and transparency (the model can explain its solution path), it may yield uneven results as the technology is refined. Developers can access these reasoning features via the Gemini API, which even supports multi-step reasoning with tools (e.g., using a calculator or calling external APIs in the middle of reasoning) for complex problem solving. Google is also applying Gemini’s reasoning to specialized domains; for example, Med-PaLM and Med-Gemini are medical LLMs that incorporate clinical reasoning patterns to better assist doctors. Overall, Google’s efforts highlight an emphasis on integrated reasoning – combining language, tool use, and planning in one model.
- DeepSeek (Open-Source Reasoning at Scale) – One of the most ambitious open efforts is DeepSeek, which in 2024-2025 introduced DeepSeek-R1, a massive 671B-parameter model purpose-built for reasoning tasks. The DeepSeek team’s approach was to start with an extremely large pre-trained base and then fine-tune it with multi-stage reinforcement learning focused on reasoning quality. They experimented with “cold-start” reinforcement learning (training a reasoning model from scratch without supervised examples) to produce DeepSeek-R1-Zero, then refined it with supervised fine-tuning and further RL to get the full DeepSeek-R1. To make this work accessible, the team distilled the giant model into a series of smaller models (ranging from 1.5B up to 70B parameters) based on popular backbones like LLaMA and Qwen. The result was a family of reasoning-optimized models that were open-sourced, immediately giving the community strong baselines to experiment with. Notably, DeepSeek-R1’s performance is comparable to OpenAI’s o1 on many reasoning benchmarks – a remarkable achievement given it’s a fully open project. DeepSeek’s released models have been used to tackle everything from logical puzzles to complex math proofs, and they continue to be a testbed for new training ideas (including contrastive methods and self-refinement techniques). This effort underscores how open collaboration can accelerate progress in areas traditionally dominated by big tech labs.
- Meta and Open-Source Models – Meta AI’s open release of LLaMA and LLaMA2 democratized LLM research, allowing the community to fine-tune and experiment with reasoning techniques on powerful base models. While Meta’s own alignment research includes reasoning about tool use and truthfulness, the open-source world has eagerly taken up the mantle. A notable example is Mistral-7B, an open 7-billion-parameter model (developed by the startup Mistral AI, founded by former Meta researchers) [5]. Despite its relatively small size, Mistral-7B excels in various reasoning benchmarks, outperforming larger models like LLaMA-2 13B in many cases [8]. For instance, Mistral-7B outscored a 13B model on commonsense reasoning tasks such as HellaSwag and Winogrande, and even on specialized math and logic benchmarks like GSM8K and MATH, it proved highly effective. It also matched or beat larger models on aggregated test suites including the Massive Multitask Language Understanding (MMLU) benchmark and Big-Bench Hard (BBH) tasks. These results show the power of architectural innovations and targeted fine-tuning: through careful training (and possibly some representation engineering under the hood) [2], a 7B model achieved what earlier took 13B+ parameters. Meta’s open models have enabled countless such projects. Moreover, techniques like token-level contrastive training have been applied on top of LLaMA-family models by academic and industry groups (as seen in the cDPO work with “LLaMA-3” models) [1]. The open-source ecosystem continues to produce specialized reasoning models and benchmarks, often sharing them freely to drive progress.
Underpinning all these efforts is a rich set of open-source benchmarks and evaluation frameworks. Researchers rely on standard reasoning challenges to measure progress and guide training. Mathematical reasoning is often evaluated with datasets like GSM8K (grade school math problems) and MATH or MATH500, which involve formal math solutions [1]. Success on these indicates an LLM can follow multi-step arithmetic and algebraic logic.
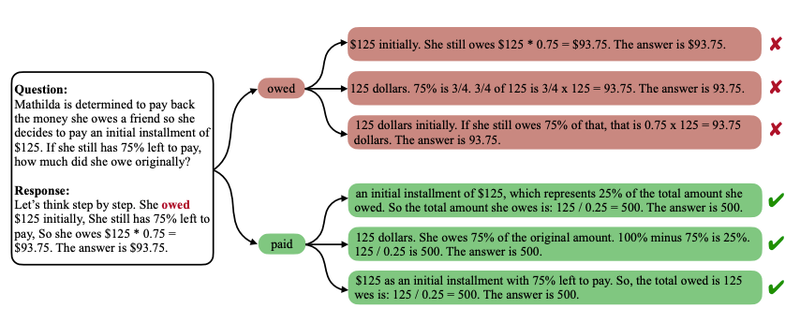
Figure: Illustration from paper “Lin et al. Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM’s Reasoning Capability - An illustration of the critical token “owed” shows that it fails to lead to the correct answer in any case. Replacing it with an alternative can significantly increase model accuracy.”
For commonsense and logical reasoning, benchmarks like HellaSwag, Winogrande, ARC (AI2 Reasoning Challenge), and CommonsenseQA are used, where models must resolve ambiguities or unstated assumptions in questions. Broad knowledge-and-reasoning tests such as MMLU (Massive Multitask Language Understanding) aggregate tasks from history to mathematics to gauge general reasoning prowess. Meanwhile, the Big Bench Hard (BBH) suite throws a kitchen sink of creative puzzles and out-of-distribution questions at models to truly test their mettle. On the engineering side, coding competitions (like Codeforces or HumanEval for coding tasks) serve as proxies for reasoning in formal domains. Notably, OpenAI and others have also created evaluation harnesses (e.g., OpenAI Evals) where new reasoning problems can be quickly defined and tested against models, often incorporating chain-of-thought analysis to see not just if the model is correct, but how it arrived at the answer. This proliferation of benchmarks – many of them open-source – ensures that claims of improved reasoning are backed by quantitative evidence, and they provide a common ground for industry and academic labs to compare notes. As models like the ones discussed above debut, their scores on GSM8K, MMLU, BBH, and beyond are closely watched indicators of whether we are closing the gap between pattern mimicry and true reasoning.
Conclusion
The push to enhance reasoning in LLMs is yielding exciting, tangible progress. By examining the problem from complementary angles – fine-grained token decisions and holistic representation dynamics – researchers have devised novel ways to make AI’s thought process more reliable. Token-level contrastive estimation (exemplified by cDPO and the identification of critical tokens) gives models a targeted nudge at the points they are most likely to fail, leading to measurable gains in accuracy on complex tasks. Representation engineering offers a window into the model’s mind and a handle to steer it, which could transform how we align AI behavior with our goals. These approaches are not merely academic; they are filtering into real systems built by OpenAI, Anthropic, Google, Meta, and open-source contributors, all eager to reduce hallucinations and increase the correctness of AI reasoning in high-stakes scenarios.
That said, the journey toward fully human-like reasoning in AI is far from over. Current LLMs, even with these improvements, can still stumble on problems a child might solve, or conversely struggle to know when to stop reasoning and deliver an answer. Future directions likely involve combining these techniques – for instance, using representation-level monitors to catch when a model is about to use a critical token, or applying contrastive training to internal representations themselves. We may also see progress in models that can explain their reasoning in more trustworthy ways, allowing users to follow the chain-of-thought (a goal closely tied to interpretability efforts in representation engineering). Additionally, expanding these methods beyond text into multimodal reasoning (images, video, and audio) will be a next frontier, as hinted by Google’s Gemini which tackles vision, text, and more in one model. The open-source community will continue to play a crucial role by developing transparent benchmarks and sharing model improvements, keeping the field honest and innovative.
Enhancing reasoning in LLMs is a multi-faceted challenge that researchers are meeting with both rigor and creativity. By focusing on what the model says to itself (tokens) and how the model thinks under the hood (representations), we are moving closer to LLMs that don’t just parrot training data, but can reason through novel problems step by step. The convergence of these advances promises AI systems that are not only more capable, but also more interpretable and aligned with human objectives. The work today – from contrastive token training to engineering of thought-vectors – is laying the groundwork for tomorrow’s AI that we can trust to reason as a true partner in solving complex problems. Each insight gained is a stepping stone toward truly intelligent AI, and the pace of research suggests many more breakthroughs are on the horizon.
References:
[1] Lin, Z., Liang, T., Xu, J., Wang, X., Luo, R., Shi, C., ... & Tu, Z. (2024). Critical Tokens Matter: Token-Level Contrastive Estimation Enhence LLM's Reasoning Capability. arXiv preprint arXiv:2411.19943. https://arxiv.org/abs/2411.19943
[2] Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., ... & Hendrycks, D. (2023). Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405. https://arxiv.org/abs/2310.01405
[3] OpenAI. “Introducing OpenAI o1 (Preview).” OpenAI Product Announcement, Sep. 12, 2024 https://openai.com/index/introducing-openai-o1-preview/ .
[4] Anthropic. “Claude’s Constitution” Anthropic News Blog, May 9, 2023. https://www.anthropic.com/news/claudes-constitution
[5] Jiang et al. “Mistral 7B”. https://arxiv.org/abs/2310.06825
[6] Schreiner, Maximilian. “Researchers improve AI logic by focusing on critical tokens.” The Decoder – AI Research News, Dec. 4, 2024. https://the-decoder.com/researchers-improve-ai-logic-by-focusing-on-critical-tokens/
[7] Raschka, Sebastian. “Understanding Reasoning LLMs: Methods and Strategies for Building and Refining Reasoning Models.” AI Magazine (blog), Feb. 5, 2025. https://sebastianraschka.com/blog/2025/understanding-reasoning-llms.html
[8] Vogt Goehring, Theia. “Representation Engineering: Mistral-7B on an Acid Trip.” VGEL blog, Jan. 22, 2024. https://vgel.me/posts/representation-engineering/
[9] Google. “Google DeepMind’s Gemini 2.0 and Flash Thinking.”, Jan. 2025. https://deepmind.google/technologies/gemini/flash-thinking/
About the author
Tim Condello is a Director of Cloud and AI/ML Services with a strong focus on artificial intelligence, machine learning, and cybersecurity. He leads enterprise AI solution development, helping customers transform business challenges into scalable, secure cloud architectures. With extensive experience at industry leaders like AWS and key roles in cybersecurity research, Tim has driven innovation across multiple sectors, empowering organizations to harness advanced AI. Connect with Tim on LinkedIn.
At The Edge Review, we believe that groundbreaking ideas deserve a global platform. Through our multidisciplinary trade publication and journal, our mission is to amplify the voices of exceptional professionals and researchers, creating pathways for recognition and impact in an increasingly connected world.
Member
%20--%3e%3c!DOCTYPE%20svg%20PUBLIC%20'-//W3C//DTD%20SVG%201.1//EN'%20'http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd'%3e%3csvg%20version='1.1'%20id='Layer_1'%20xmlns='http://www.w3.org/2000/svg'%20xmlns:xlink='http://www.w3.org/1999/xlink'%20x='0px'%20y='0px'%20viewBox='0%200%20200%2067.9'%20style='enable-background:new%200%200%20200%2067.9;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill:%234F5858;}%20.st1{fill:%233EB1C8;}%20.st2{fill:%23D8D2C4;}%20.st3{fill:%23FFC72C;}%20.st4{fill:%23EF3340;}%20%3c/style%3e%3cg%3e%3cg%3e%3cg%3e%3cg%3e%3cpath%20class='st0'%20d='M76.1,37.5c-0.4-2.6-2.9-4.6-5.8-4.6c-5.2,0-7.2,4.4-7.2,9.1c0,4.4,2,8.9,7.2,8.9c3.6,0,5.6-2.4,6-5.9H82%20c-0.6,6.6-5.1,10.8-11.6,10.8c-8.2,0-13-6.1-13-13.7c0-7.9,4.8-14,13-14c5.8,0,10.7,3.4,11.4,9.5H76.1z'/%3e%3cpath%20class='st0'%20d='M84,35.9h5v3.6h0.1c1-2.4,3.6-4.1,6.1-4.1c0.4,0,0.8,0.1,1.1,0.2v4.9c-0.5-0.1-1.3-0.2-1.9-0.2%20c-3.9,0-5.2,2.8-5.2,6.1v8.6H84V35.9z'/%3e%3cpath%20class='st0'%20d='M106.4,35.4c6,0,9.9,4,9.9,10.1c0,6.1-3.9,10.1-9.9,10.1c-6,0-9.9-4-9.9-10.1%20C96.5,39.4,100.4,35.4,106.4,35.4z%20M106.4,51.6c3.6,0,4.7-3.1,4.7-6.1c0-3.1-1.1-6.1-4.7-6.1c-3.6,0-4.6,3.1-4.6,6.1%20C101.8,48.6,102.8,51.6,106.4,51.6z'/%3e%3cpath%20class='st0'%20d='M122.4,48.9c0,2.3,2,3.2,4,3.2c1.5,0,3.4-0.6,3.4-2.4c0-1.6-2.2-2.1-6-3c-3-0.7-6.1-1.7-6.1-5.1%20c0-4.9,4.2-6.1,8.3-6.1c4.2,0,8,1.4,8.4,6.1h-5c-0.1-2-1.7-2.6-3.6-2.6c-1.2,0-2.9,0.2-2.9,1.8c0,1.9,3,2.1,6,2.9%20c3.1,0.7,6.1,1.8,6.1,5.4c0,5-4.4,6.7-8.7,6.7c-4.4,0-8.8-1.7-9-6.7H122.4z'/%3e%3cpath%20class='st0'%20d='M141.6,48.9c0,2.3,2,3.2,4,3.2c1.5,0,3.4-0.6,3.4-2.4c0-1.6-2.2-2.1-6-3c-3-0.7-6.1-1.7-6.1-5.1%20c0-4.9,4.2-6.1,8.3-6.1c4.2,0,8,1.4,8.4,6.1h-5c-0.1-2-1.7-2.6-3.6-2.6c-1.2,0-2.9,0.2-2.9,1.8c0,1.9,3,2.1,6,2.9%20c3.1,0.7,6.1,1.8,6.1,5.4c0,5-4.4,6.7-8.7,6.7c-4.4,0-8.8-1.7-9-6.7H141.6z'/%3e%3cpath%20class='st0'%20d='M156.1,35.9h5v3.6h0.1c1-2.4,3.6-4.1,6.1-4.1c0.4,0,0.8,0.1,1.1,0.2v4.9c-0.5-0.1-1.3-0.2-1.9-0.2%20c-3.9,0-5.2,2.8-5.2,6.1v8.6h-5.3V35.9z'/%3e%3cpath%20class='st0'%20d='M174.2,46.8c0.1,3.3,1.8,4.9,4.7,4.9c2.1,0,3.8-1.3,4.1-2.5h4.6c-1.5,4.5-4.6,6.4-9,6.4%20c-6,0-9.8-4.1-9.8-10.1c0-5.7,4-10.1,9.8-10.1c6.5,0,9.7,5.5,9.3,11.4H174.2z%20M182.7,43.5c-0.5-2.7-1.6-4.1-4.2-4.1%20c-3.3,0-4.3,2.6-4.4,4.1H182.7z'/%3e%3cpath%20class='st0'%20d='M190.9,39.5h-3.1v-3.5h3.1v-1.5c0-3.4,2.1-5.8,6.4-5.8c0.9,0,1.9,0.1,2.8,0.1v3.9c-0.6-0.1-1.3-0.1-1.9-0.1%20c-1.4,0-2,0.6-2,2.2v1.1h3.6v3.5h-3.6v15.6h-5.3V39.5z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cpolygon%20class='st1'%20points='0,67.9%200,47.4%2016.8,41.9%2046.6,52.1%20'/%3e%3cpolygon%20class='st2'%20points='29.8,26.1%200,36.4%2016.8,41.9%2046.6,31.7%20'/%3e%3cpolygon%20class='st0'%20points='16.8,41.9%2046.6,31.7%2046.6,52.1%20'/%3e%3cpolygon%20class='st3'%20points='46.6,0.2%2046.6,20.6%2029.8,26.1%200,15.9%20'/%3e%3cpolygon%20class='st4'%20points='29.8,26.1%200,36.4%200,15.9%20'/%3e%3c/svg%3e)
Important Links
Contact Info
info@theedgereview.org
Address:
14781 Pomerado Rd #370, Poway, CA 92064