The Long Context Conundrum: Challenges and Innovations in Scaling LLM Memory




In an era where AI assistants are expected to digest entire novels, multi-document dossiers, or hours of conversation, the demand for longer-context large language models (LLMs) is soaring. Top AI companies are racing to expand context windows: OpenAI’s GPT-4 introduced 32,000-token versions, Anthropic’s Claude leapt from a 9K to 100K token window (and later to 200K), and startups like AI21 have unveiled models with 256K-token capacity [1]. Google DeepMind is reportedly aiming even higher, with hints of million-token contexts in its upcoming Gemini model [1]. These numbers promise that an LLM could ingest hundreds of pages or hours of transcribed audio in one go. But with great context comes great computation – extending an LLM’s memory isn’t as simple as turning a dial. Each additional token in context exacts a steep cost in processing time and memory usage. The long-context conundrum is emerging as one of the toughest challenges in scaling AI capabilities.
This article explores why supporting ultra-long contexts in LLMs is so challenging and how researchers are innovating to break through. We’ll dive into the computational complexity that makes naive long-context processing prohibitive and then examine cutting-edge strategies that aim to overcome these limits. From sparse attention schemes that skip over irrelevant words, to LongRoPE positional embeddings that stretch model memory without retraining, to chunking and fusion techniques that process text in pieces, we’ll explain how each approach works. We’ll also venture beyond text, looking at how models handle multimodal context – think entire image galleries or lengthy videos – using tricks like variable frame sampling and an “Eclipsed Attention” strategy to focus on the salient parts. Along the way, we’ll reference industry benchmarks such as the Needle-In-A-Haystack test (NIAH) to see how today’s leading models (from OpenAI, Anthropic, Meta, DeepSeek, and Google DeepMind) stack up in long-context tasks. Finally, we’ll summarize recent advancements and what they tell us about the future of large LLM context windows.
By the end, you’ll have a clear picture of both the promise and the perils of pushing context lengths to extremes. The ability for AI to remember more can unlock powerful new applications – from analyzing lengthy legal contracts to powering assistants that recall every detail of your interactions. But it also requires reimagining architectures and algorithms to avoid simply drowning in data. Let’s begin with why exactly long contexts cause headaches for today’s transformers.
The Computational Challenge of Long Contexts
At the heart of an LLM’s language prowess is the attention mechanism, which allows the model to weigh relationships between words (or tokens) in a sequence. Traditional attention, however, doesn’t scale gracefully. In a vanilla Transformer, attention computation grows quadratically with the number of tokens – doubling the context length makes the attention work roughly four times harder. This is because every token compares itself to every other token to decide what to “pay attention” to. As a result, if an LLM can just handle a 512-token input, pushing it to 5,000 tokens would multiply the computations by nearly 100 (and similarly balloon the memory usage) [2]. In practical terms, processing a book chapter instead of a page can swamp even the most powerful GPUs.
Another major strain comes from the Key-Value (KV) cache – the model’s short-term memory for attention. As an LLM reads more context, it has to store a key and value vector for each token at each layer. This storage grows linearly with context length and model size. For a large model with dozens of layers and thousands of hidden dimensions, a context jump from 4K to 100K tokens can mean tens of gigabytes of extra data to stash. For example, Anthropic reported feeding The Great Gatsby (72K tokens) to Claude took about 22 seconds [3]; behind that speedy response was an immense amount of matrix math and memory juggling to keep track of all those words. The latency and cost implications are huge – some providers estimate that a single 100K-token prompt can cost on the order of $0.50 in cloud compute fees, whereas a small prompt costs mere fractions of a cent. Long contexts can thus burn both time and money if handled naively.
This quadratic time complexity and massive memory footprint create a brick wall for long-context scaling. Pushing context length from thousands to hundreds of thousands of tokens isn’t just a matter of adding more GPUs; it demands fundamentally new approaches. Otherwise, an “infinite context” model would require infinite compute – clearly a non-starter. Developers also observe that beyond a certain length, model quality may degrade even if it doesn’t crash, because the attention scores can get diluted or destabilized when too many tokens are in play. In summary, the computational challenge of long contexts is twofold: explosive growth in operations and memory, and potential diminishing returns in model accuracy. Overcoming this means rethinking how an LLM processes information – finding shortcuts to pay attention more efficiently, and clever ways to manage or reduce the memory per token.
The silver lining is that humans and algorithms rarely need to treat every part of a long input equally. Just as a reader skims a lengthy report, focusing on key sections and skipping fluff, an LLM might not actually need a fully detailed comparison of every token with every other. This intuition has driven researchers to develop a toolbox of strategies to approximate or constrain the attention mechanism for long sequences. Let’s explore some of the most promising innovative techniques for scaling context length and how they chip away at the quadratic barrier.
Innovative Techniques for Scaling Context Length
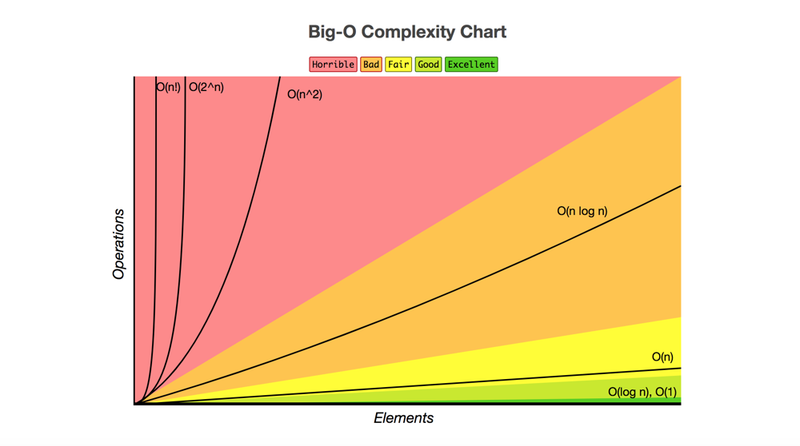
Sparse attention patterns reduce computation by limiting which tokens interact. For example, BigBird uses a mix of local “window” attention (blue), a few “global” tokens (green) that everyone can see, and some random connections (orange). This achieves similar effect as full attention but with linear complexity [4].
Sparse Attention – Taming the Bandwidth Beast
One of the most powerful ideas is to make attention sparse: don’t let every token attend to every other. Instead, define a pattern or rule so that each token only exchanges information with a limited subset of others. By cutting out most of those pairwise comparisons, the model dramatically reduces computation while hopefully still catching the important dependencies. Think of reading a book: you don’t re-read every page each time you turn to a new chapter; you keep track of key plot points and refer back only to those. Sparse attention tries to mimic this behavior by connecting tokens in a sparser graph rather than an all-to-all web.
Several sparsity patterns have been tried. A common approach is local (sliding window) attention, where each token only attends to neighbors within a fixed window (e.g. 256 tokens to the left/right). This ensures each word sees context in its vicinity (like a sentence or paragraph) but not things far away. Another is global attention, where a few special tokens (or positions) have access to the whole sequence – these can act like summary nodes or topic markers that broadcast important info. And some models add random attention on top – connecting tokens at random intervals – to ensure no part of the sequence is completely isolated [4]. The following figure illustrates these with BigBird’s approach: combining global tokens, local windows, and random links to approximate full attention. The outcome is a sparse attention matrix where most entries are zero (ignored). Impressively, this can bring complexity down from O(n²) to O(n) or O(n * log n) in many cases, enabling sequences 8× longer than before on the same hardware. Research from Google (BigBird) and others (Longformer, Reformer) showed that with the right sparse pattern, models could handle sequences of several thousand tokens with similar performance to full-attention models, but far less compute.
The trade-off is that designing a sparse pattern is task-dependent – you have to guess which parts of the context will be relevant. Too sparse a pattern might miss an important long-range connection (just as a reader might skip a critical footnote). Nonetheless, in practice sparse attention has become a go-to technique for extending context. Anthropic’s 100K-token Claude model is believed to use some form of sparse or sliding window attention to make such a huge context feasible. DeepSeek’s recent LLMs also boast a “Native Sparse Attention” mechanism that prunes the attention graph dynamically, and others refer to a collection of these methods as an “Eclipsed Attention” strategy – essentially eclipsing portions of the input from attention to save computation. By intelligently deciding where not to look, LLMs can focus their compute on the most pertinent parts of a long input. Sparse attention is thus a key pillar in long-context support.
LongRoPE – Extending the Positional Horizon
Even if we solve the attention compute problem, another issue arises when lengthening context: the model’s sense of position can break down. Most LLMs use positional encodings to know the order of tokens, such as Rotary Position Embeddings (RoPE) in GPT models. These encodings are often trained for a maximum length (e.g. 2048 tokens). If you suddenly feed a 100K token sequence to a model only trained on 4K positions, it faces out-of-distribution position indices – kind of like asking someone to count far beyond what they’ve ever counted before, leading to errors (the infamous “positional drift”). This can introduce catastrophic values or instability in the attention scores [5], so even if the model architecture could handle more tokens in theory, it might not actually understand token 50,000’s role relative to token 50.
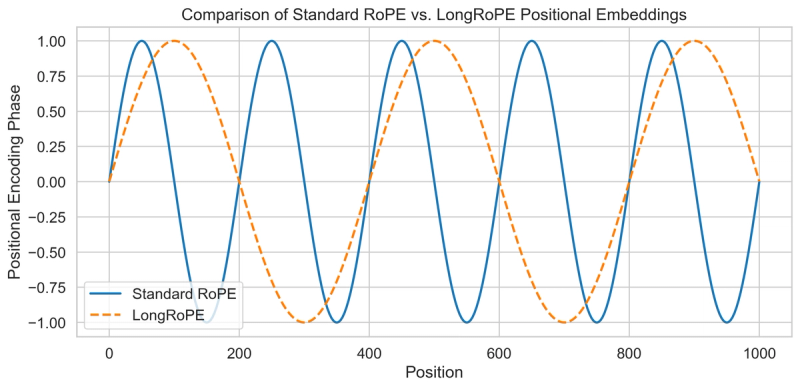
Enter LongRoPE, a recent technique from Microsoft researchers that addresses this positional encoding limit. LongRoPE (short for “long-range RoPE”) cleverly rescales the rotary embedding at inference time (and with minimal fine-tuning) to extend the model’s positional range dramatically [6]. In essence, it interpolates or stretches the existing position embeddings in a non-uniform way such that the model can be fed positions far beyond what it saw in training. The LongRoPE team demonstrated extending a pre-trained Llama2 model’s context window from 128K to an astonishing 2,048K tokens (2 million!) with only about 1,000 additional training steps [5]. The model retained its performance on short inputs while now being able to handle truly massive sequences. The magic lies in a two-step process: first, fine-tune the model on a moderately extended length (say 256K) to learn not to freak out at longer sequences; then apply a carefully computed interpolation to the RoPE that maps ultra-long positions into the range the model learned. By readjusting the frequency spectrum of the positional embedding, LongRoPE prevents the attention weights from degenerating over long distances. In the following figure, the x-axis represents the token positions in a sequence, and the y-axis represents the phase value of the positional embedding. For the Standard RoPE curve, the sine wave oscillates with a fixed period (here, 200 units) showing rapid cyclical behavior. Whereas for LongRoPE, with an increased period (here, 400 units), the sine wave oscillates more slowly, illustrating how LongRoPE “stretches” the positional encoding to handle longer contexts without drastic phase changes.
LongRoPE is essentially a way to hack the model’s sense of position to buy more context length without a proportional increase in training cost. It’s part of a broader trend of techniques aiming for length extrapolation – getting models to generalize to longer sequences than seen in training. Other methods in this vein include position embedding extrapolation schemes used in Meta’s long-context LLaMA variants and OpenAI’s research into making GPT-4 “8K-aware” so it could be reliably extended to 32K. The impressive part about LongRoPE is the scale (millions of tokens) and the minimal retraining required. It suggests that, at least in terms of positional understanding, we can push limits much further if we’re careful about how we encode positions. Of course, a 2M token input might still be impractical computationally with standard attention – which is why LongRoPE would be combined with sparse attention and other tricks. But it shows that positional encodings need not be the bottleneck for context length; we can teach an old model new positions, so to speak.
Chunked Processing – Divide and Conquer the Context
Another intuitive strategy is chunking: break a very long input into smaller chunks that the model can digest one at a time. This is somewhat akin to how one might read and summarize a long report section by section rather than trying to absorb it all at once. In the context of LLMs, chunked processing can take a few forms. A simple approach is a sliding window or chunk-and-summarize: feed the first chunk of text, get some intermediate summary or state, then move the window forward (some overlap may be kept between chunks to maintain continuity) and feed the next chunk along with the summary. By doing this iteratively, the model never sees the entire 100K tokens at once, but ideally it maintains a running understanding. Many long-document question-answering systems use this approach: the document is split into chunks that fit the model (say 4K tokens each), each chunk is processed for relevant info, and then a final answer is produced from the aggregated info.
More advanced is a hierarchical chunking approach: you might have the LLM process chunks independently at a first layer, then another model or another pass that fuses the knowledge from those chunks (we’ll discuss context fusion next). For example, if you have 10 chapters of a book, you could ask the model to produce an “embedding” or vector representation of each chapter, and then run a second-stage model that attends to those 10 embeddings to answer a question about the whole book. By dividing the input, you dramatically cut the per-pass sequence length (each chapter individually might be manageable), at the cost of potentially losing some cross-chapter details unless the fusion step recovers them.
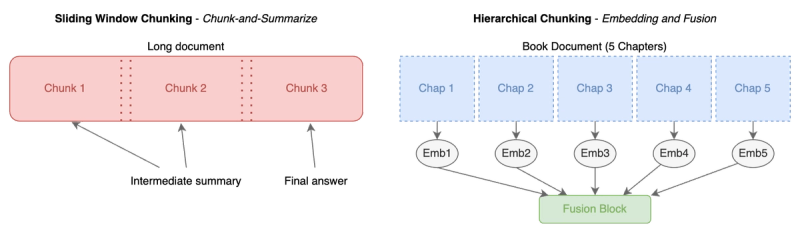
Chunked context processing trades off completeness for tractability. It ensures that at no point is the model’s active context beyond a manageable size. Enterprises have found this useful to deploy LLMs on long documents: instead of one giant prompt, they orchestrate multiple prompts. However, chunking alone is not a perfect solution because the model doesn’t natively capture interactions between tokens in different chunks. If an answer requires connecting information from page 5 and page 50 of a report, a naive chunking scheme might miss that connection if those pages were processed separately. This motivates the next technique – after dividing, we need to conquer by stitching knowledge back together.
Context Fusion – Weaving the Threads Back Together
Context fusion refers to methods for recombining information from multiple processed chunks so that the model can produce a coherent overall output. It’s essentially the second half of the divide-and-conquer strategy. Once an LLM has digested chunks of input, how do we make sure it can synthesize across them? One approach is what we hinted at: have a hierarchical model where a top-level attention runs over the summaries or embeddings of each chunk. This might be a smaller attention mechanism that deals with, say, 100 chunk representations instead of 100,000 individual token embeddings. Since each chunk representation condenses that chunk’s content, the model can reason about relationships between chunks (like “Chapter 1 and Chapter 7 both mention the CEO’s resignation, which is crucial to the question”). This technique can be thought of as creating a document map that the model navigates, rather than wandering every page individually.
Another approach to fusion is via iterative refinement. For example, after an initial read-through in chunks, you could prompt the model with something like: “Given the analysis of each section above, answer the overall question.” The model then has to draw on the intermediate outputs (which you include in a final prompt) to produce a final answer. Some systems use tools or memory outside the model, like vector databases, to store chunk information and then retrieve the most relevant chunks for a query – a form of retrieval-augmented fusion.
Regardless of implementation, the goal is to retain global coherence. Without fusion, chunking might leave the model with tunnel vision on a small window. Context fusion ensures the pieces are woven into a whole. In the best case, a user shouldn’t be able to tell that the model read the input in segments – the answer should be as consistent and informative as if the model had read the entire input at once (if not more so, since it might actually avoid being overwhelmed by unimportant details). Some recent long-context architectures explicitly build in multi-stage attention: for example, MosaicML’s MPT-7B-Storywriter (an LLM for long fiction) keeps separate attention modes for local coherence and global story context. Similarly, DeepMind’s Perceiver architecture processes very long inputs by first projecting them into a smaller set of latent units, effectively performing context fusion by design. The theme here is summarize and merge – compress chunks, then let the model attend to those compressed representations to get the big picture.
Token Eviction – Strategic Forgetting to Free Memory
Even with chunking and sparse attention, an LLM’s KV cache (memory) can remain a bottleneck if the context is extremely long. Think of the KV cache as a shelf that holds all the tokens the model is remembering. Token eviction is the idea of occasionally clearing out the least useful items from this shelf to make room for new ones. Just as a computer operating system might swap out old memory pages, an LLM could drop tokens that are deemed no longer relevant to the current task. This is a form of memory management inside the model’s inference process.
How might the model decide what to evict? It needs a scoring function for token importance [7]. One simple heuristic is to remove the oldest tokens first (a recency-based eviction, akin to a sliding context window that only keeps the last N tokens). But oldest isn’t always least relevant – the start of a story might be crucial to the ending! More sophisticated approaches score tokens by how much they contribute to the next predictions or how much attention other tokens pay to them. For instance, if certain tokens have very low attention weights from all other tokens, the model might safely forget them. Or if a section of text has been summarized and the summary stored, the model might evict the detailed tokens and retain only the summary in memory.
Recent research ideas even explore dependency tracking: ensuring that if token X depends on token Y which was evicted, you also evict X or somehow record the dependency to avoid inconsistency [7]. The benefit of token eviction is that it bounds the memory usage – the model maintains a rolling window of context, discarding fluff as it goes. This can allow effectively infinite streams of input, at the cost of forgetting some specifics. It’s a bit like how humans can continue to process very long texts by taking notes and discarding exact wording from earlier chapters once they’ve got the gist.
One concrete example is in Retentive Networks (RetNet), a new architecture from Microsoft that replaces attention with a retention mechanism. RetNet’s design inherently decays old token influence, which is analogous to evicting tokens gradually (it’s baked into the model via learned decay rates). Another example is OpenAI’s early research on feedforward memory streams, where they limited how long a token stays in the “active” memory of the model. These are early-stage ideas, but they align with the token eviction concept. In practice, implementing token eviction in a transformer is tricky – you have to make sure the model’s later layers don’t suddenly try to attend to something that’s been thrown away. But if done correctly, it can be a game-changer for long-running conversations or continuous data streams, allowing the model to forget safely. As one article put it, token eviction is about “freeing up memory strategically” – dropping the low-value tokens so the model can focus on what matters.
Together, these techniques – sparse attention, long-range position interpolation (LongRoPE), chunking with fusion, and token eviction – form a suite of strategies that are often combined (sometimes all at once) in cutting-edge long-context LLMs. In fact, the term “Eclipsed Attention” has been used to describe such a combined approach, where different parts of the context are eclipsed (occluded) from full view according to need, enabling the model to handle dramatically longer inputs within reasonable resource limits. The engineering art is in balancing these tricks to maximize useful context and minimize any loss in answer quality. So how well are these approaches working in practice? To answer that, we turn to benchmarks that stress-test LLMs on long input tasks.
Multimodal Context Expansion
Thus far we’ve focused on long text, but modern LLMs are increasingly multimodal – they can take in images, audio, video, and more as part of their “context.” This expansion multiplies the challenge of long contexts, because non-text data can be extremely data-heavy. For example, one high-resolution image might be equivalent to thousands of tokens if described in detail, and a 5-minute video might contain hundreds of frames. Naively feeding every pixel of every frame into an LLM would blow up the context length beyond anything text-only models deal with. So, how do we efficiently handle long-context image and video inputs? The answer: many of the same ideas (sparsity, chunking, etc.) apply, along with modality-specific tricks like variable sampling of data and specialized attention mechanisms for multimodal streams.
One key technique is variable frame sampling for video. Instead of treating a video as a uniform sequence of frames (which would yield, say, 150 frames per minute, many nearly identical), systems intelligently sample frames at varying rates. For instance, in a slow scene, they might take one frame per second, but in a fast-changing scene, maybe five frames per second – focusing on capturing new information. This reduces the total number of frame inputs. Similarly, an image might be processed not as a flat grid of pixels but as a set of objects or regions of interest (using an object detection model first), thereby yielding a variable number of “tokens” per image (more tokens for complex images, fewer for simple ones). Such adaptive sampling ensures that the model’s context isn’t cluttered with redundant visual data.
Multimodal LLMs also employ forms of sparse attention tuned for vision-language data. A recent system called mPLUG-Owl3 introduced hyper attention blocks that efficiently integrate long image sequences with text, drastically cutting inference time and memory usage (by ~88% and ~48% respectively, compared to naive approaches) [8]. The idea is that the model doesn’t attend every text token to every pixel; instead, it uses a grouped attention where images are first processed in their own vision encoder (with local attentions), and only condensed visual features attend to text (and vice versa) in a controlled manner. This is akin to chunk-and-fuse, but specialized for multimodal data: each image or frame is a chunk that gets encoded, and then a fusion layer merges the sequence of image embeddings with the text embeddings. By limiting the cross-modal attention to higher-level features (like “scene descriptors” rather than raw pixels), these models handle long image sequences far more efficiently.
Another interesting development enabling long multimodal context is combining alternative architectures. The LongLLaVA project, for instance, built a hybrid model with both transformer and Mamba (state-space model) components, achieving the ability to process nearly 1,000 images on a single 80GB GPU [9]. Mamba (inspired by the MAMBA architecture for unlimited text context) can handle long sequences with linear complexity, so mixing it with a transformer allows the system to retain performance while extending length. The result: LongLLaVA could input 933 images (with some resolution trade-offs) in one go. For reference, that could be an entire photo album worth of images provided as context to an AI assistant – something standard vision transformers would choke on. Similarly, on the text side, researchers developed V2PE (Variable Visual Position Encoding) to push multimodal context windows even further: by adjusting how visual token positions are encoded, they trained a model that when given sequences up to 256K tokens during fine-tuning could generalize to 1 million token multimodal inputs [10]. This was demonstrated on a multimodal version of the NIAH benchmark, showing that even vision-language models can achieve extreme context lengths when their position encodings and training data are scaled appropriately.
In less technical terms, handling images and video in long contexts boils down to skipping and focusing: skip over parts of the visual input that are repetitive or not informative (via variable sampling), and focus computation on the parts that are (via sparse or hierarchical attention). The notion of “Eclipsed Attention” can be extended here – for example, you might eclipse the background of images so that only foreground objects attend to the text, or eclipse frames of video that don’t change much, only periodically allowing a full attention update on a keyframe. The model, therefore, doesn’t waste cycles comparing one static camera frame to the next nearly identical one. We also see multi-scale processing in video: first detect shot boundaries (chunk the video by scene), then within each scene focus on keyframes, then fuse scene information for an overall understanding. All these methods ensure that as inputs get richer (imagine an AI that reads a PDF with embedded charts and images), the effective context that the transformer deals with is managed smartly.
To sum up, multimodal long-context handling is an active area of research, borrowing many ideas from text long-context and adding new ones. Giants like Google DeepMind are likely combining these approaches in models like Gemini – for example, using a form of sparse attention where text and image tokens have limited interactions unless necessary. The progress is rapid: what was impossible a year ago (like feeding 100 images into a chat model) is now achievable with careful system design. As models become “eyes and ears” in addition to being readers, these multimodal context innovations will be crucial to ensure they can scale their understanding without faltering.
Benchmarking Long-Context Performance
It’s one thing to have a model that accepts a 100K token input without crashing, but does it truly understand and utilize that long context? To answer this, the community relies on specialized benchmarks. The most widely referenced is the Needle-In-A-Haystack (NIAH) test [1]. In a typical NIAH setup, the model is given a very long text with a tiny “needle” of crucial information buried somewhere in it, and asked a question that can only be answered using that needle. For example, one might insert a single relevant sentence into 100 pages of random text and then ask a question whose answer is in that sentence. A model with a genuine long-context capability should retrieve that nugget and answer correctly, whereas a shorter-context model or one that effectively forgets earlier tokens will fail as the needle slips out of its attention span.
NIAH tests have been a quick way to check if an LLM’s extended context is working. Early results were promising: both GPT-4 (with its 32K context version) and Claude 2 (100K context) could perfectly find needles even as the haystack length grew to tens of thousands of tokens [11]. In fact, in one evaluation, Claude and GPT-4 scored near 100% on NIAH-style retrieval at all tested lengths, meaning they successfully fished out the key detail no matter how much irrelevant text surrounded it. This demonstrates that technically, the models can carry specific information from the distant past of the prompt and use it when asked.
However, critics quickly pointed out that NIAH is a narrow test. It checks memory retrieval but not deeper reasoning or understanding. A model might pass NIAH by essentially learning “whenever I see a question, scan back for the answer pattern” – a bit like an open-book exam where you know exactly what page to find an answer on. Real-world tasks are often more complex: they require reasoning across the entire breadth of a document, aggregating pieces of info, or handling irrelevant distractors gracefully. It turned out that many models with extended windows could carry a single fact across long distances, but struggled on tasks requiring synthesis or reasoning over long contexts.
To address this, newer benchmarks emerged. Anthropic and others have discussed an “effective context length” – the length up to which a model can maintain high-quality responses – as potentially much shorter than the maximum length. NVIDIA researchers introduced RULER, a benchmark testing Retrieval, Multi-hop reasoning, List operations (aggregation), and Question answering in long contexts. RULER provides a way to measure not just if the model can find a needle, but can it do complex reasoning when the supporting facts are scattered across a long text. They define a “passing grade” as 85% success, and then see what’s the longest context at which the model can still hit that score. The results have been telling: many models show a sharp drop in performance well before their theoretical limit. For instance, a model advertised with 100K context might only effectively reason up to 20K before making errors, after which it just carries extra tokens like dead weight.
Empirical comparisons across leading LLMs have revealed big differences in long-context prowess. OpenAI has been somewhat conservative – GPT-4’s 32K model performs reliably within that range, but OpenAI hasn’t (publicly) pushed beyond that yet. Anthropic’s Claude 2.1, with a 200K window, could handle very long transcripts but initial versions showed quality issues beyond 100K (thus their two models “Claude 3.5 Sonnet” vs “Claude 3 Haiku” where one favors length, one quality). AI21’s Jamba models, built on the Mamba architecture, tout that their effective context equals the claimed 256K – essentially no loss in quality up to that length – which if verified is a major achievement and possibly due to their state-space model approach. On the other hand, open-source models like LLaMA-2 long-context variants (up to 128K via position interpolation) often see degraded accuracy on tasks like QA as context grows; one study found a LLaMA2-70B started dropping in score after around 32K tokens, even though it could accept 128K tokens. This suggests that architecture and training data play a huge role – it’s not enough to bolt on a long positional embedding; the model should be trained or fine-tuned to make use of long-range info.
A concrete data point from enterprise tests: Snorkel AI reported that GPT-4 (32K) and Claude 2.1 (100K) both aced a synthetic NIAH test (finding a random “best thing to do in San Francisco” line hidden among unrelated essays) at all lengths, yet on their more realistic long-document QA benchmark, GPT-4’s accuracy was only ~59% and Claude’s was similar, indicating difficulties in deeper comprehension [11]. In other words, perfect memory of a fact doesn’t equate to perfect understanding of a long text’s content. Models might miss subtle cues, get tricked by irrelevant sections, or fail to chain together multiple pieces of info that are far apart.
The ongoing advancements in long-context LLMs are trying to close this gap. Training on longer texts helps – e.g., if a model sees 100-page documents during training, it learns to not lose thread over long spans. Techniques like those we discussed (sparse attention, etc.) also aim to preserve quality by not overwhelming the model with noise. And when all else fails, hybrid approaches (retrieval augmentation, etc.) can complement the model – for example, using a vector database to fetch relevant parts of a long text, then feeding those to the model in a shorter prompt. This has led some to question: with powerful retrieval, do we need extremely long context at all? It’s a debate of RAG (Retrieval-Augmented Generation) vs raw long context. In practice, many foresee a synergy: LLMs with moderately long context (perhaps 16K-100K) aided by retrieval for truly gigantic info corpora.
In summary, benchmarks like NIAH have been crucial stepping stones – they proved these models can handle long contexts in principle. More comprehensive tests like RULER and real-world trials show there’s still work to do to make that ability robust and consistently useful. It’s an exciting time: every few months, a new record in context length or a new benchmark result is announced, as models inch closer to that dream of “reading and reasoning over an entire book” seamlessly. Next, we conclude with key takeaways and what the future might hold for this fast-evolving corner of AI.
Conclusion
The push for ever-longer context windows in LLMs is driven by clear needs – from legal AI that digests thousands of pages of contracts, to coding assistants that handle entire codebases, to multimodal agents that analyze hours of video. But unlocking this capability has demanded equally clear-eyed innovation. We’ve seen that the quadratic scaling of attention was a fundamental roadblock, making naive long-context processing exorbitantly expensive. In response, the field rallied with a toolkit of strategies: sparse attention to cut down computation by ignoring irrelevant token interactions, clever positional encoding tricks like LongRoPE to stretch models’ memory without breaking their understanding, chunking and context fusion pipelines to break tasks into manageable pieces and then aggregate the results, and token eviction to manage the model’s memory footprint by discarding less important information. In multimodal scenarios, these ideas extend further with adaptive techniques to handle images and videos, ensuring that an AI doesn’t drown in visual data when the “context” includes everything your camera saw today.
These advances are beginning to pay off. Industry models have rapidly expanded their advertised context lengths (from 2K in GPT-3 to 100K+ in Claude and 256K in AI21’s Jamba), and research prototypes have blown past the million-token mark. Benchmarks like NIAH show that, at least for simple recall, today’s LLMs can utilize huge contexts effectively – a remarkable achievement. Yet, the story is far from over. Effective context length – where the model retains high reasoning ability – is often trailing the raw capacity. The challenge moving forward is making every token count: ensuring that if we give a model 100K tokens of input, it leverages them intelligently, without losing the thread or wasting effort. This likely means more training on long sequences, more refined attention patterns that dynamically adjust to content, and perhaps new architectures that move beyond the transformer paradigm (like state-space models or hybrids) to handle long-term dependencies better.
Another frontier is efficient inference. It’s one thing to allow a long context, another to serve it to millions of users. Techniques like FlashAttention (which optimizes attention computation) and memory-efficient architectures will be vital to bring long-context LLMs into production use at scale. We may also see specialization: not every model needs a 100K window for every task. Perhaps AI assistants will learn to recognize when to engage a long-context mode (e.g., upon detecting the user has pasted a long document) and otherwise operate in a faster, short-context mode. This kind of adaptive behavior could give the best of both worlds – speed and depth on demand.
In the multimodal realm, the integration of long-context techniques means future AI systems could ingest not just a long document, but an entire mixed-media dossier – images, tables, audio transcripts – and make sense of it holistically. The context fusion of different data modalities is an exciting extension of what we discussed, and it’s already on the horizon with models like GPT-4 Vision and Gemini aiming to seamlessly handle text+visual input. Long-context benchmarks will also evolve: beyond NIAH and RULER, we’ll have challenges that include browsing large websites, wading through months of chat logs, or analyzing lengthy sensor data streams.
Ultimately, the quest for longer context in LLMs is about pushing towards more human-like comprehension. Humans can read long novels (albeit slowly) and recall earlier plot points when they matter; we take notes, we skim, we focus – all strategies mirrored in the techniques above. Each new method brings LLMs a step closer to that level of contextual mastery. The journey isn’t easy – it’s a high-wire act balancing memory and compute – but the progress in just the last two years has been staggering. As one research blog wryly noted, “the future is long (context)”. Indeed, the ability to handle long contexts will likely become a standard feature of the next generation of AI, enabling deeper knowledge, less fragmentation of tasks, and more fluid multi-turn interactions. The haystacks are only getting bigger in our information-rich world; thankfully, our AI needles are sharpening too, ready to find insight in the noise, one long prompt at a time.
References:
[1] Long Context, But Actually | AI21. https://www.ai21.com/blog/long-context-yoav-shoham
[2] Understanding BigBird's Block Sparse Attention. https://huggingface.co/blog/big-bird
[3] Introducing 100K Context Windows | Anthropic. https://www.anthropic.com/news/100k-context-windows
[4] BigBird Explained | Papers With Code. https://paperswithcode.com/method/bigbird
[5] Microsoft’s LongRoPE Breaks the Limit of Context Window of LLMs, Extents it to 2 Million Tokens. https://syncedreview.com/2024/02/25/microsofts-longrope-breaks-the-limit-of-context-window-of-llms-extents-it-to-2-million-tokens/
[6] Ding, Yiran, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang and Mao Yang. “LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens.” ArXiv abs/2402.13753 (2024): n. pag.
[7] Eclipsed Attention and the Future of Long-Context LLMs. https://luminary.blog/techs/eclipsed-attention/
[8] Ye, Jiabo, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. "mplug-owl3: Towards long image-sequence understanding in multi-modal large language models." In The Thirteenth International Conference on Learning Representations. 2024.
[9] Wang, Xidong, Dingjie Song, Shunian Chen, Chen Zhang, and Benyou Wang. "LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via a Hybrid Architecture." arXiv preprint arXiv:2409.02889 (2024).
[10] Ge, Junqi, Ziyi Chen, Jintao Lin, Jinguo Zhu, Xihui Liu, Jifeng Dai, and Xizhou Zhu. "V2PE: Improving Multimodal Long-Context Capability of Vision-Language Models with Variable Visual Position Encoding." arXiv preprint arXiv:2412.09616 (2024).
[11] Long context models in the enterprise: benchmarks and beyond. https://snorkel.ai/blog/long-context-models-in-the-enterprise-benchmarks-and-beyond/
About the author
Anjanava Biswas is an award-winning senior AI specialist solutions architect at Amazon Web Services (AWS), a public speaker, and author with more than 16 years of experience in enterprise architecture, cloud systems and transformation strategy. He is dedicated to artificial intelligence, machine learning and generative AI research, development and innovation projects for the past seven years, working closely with organizations from the healthcare, financial services, technology startup and public sector industries. Biswas holds a Bachelor of Technology degree in information technology and computer science and is a TOGAF certified enterprise architect. He also holds seven AWS Certifications. Biswas is an INFORMS member, Senior IEEE member and a fellow at IET (UK), BCS (UK) and IETE (India). Connect with Anjanava Biswas on LinkedIn.
At The Edge Review, we believe that groundbreaking ideas deserve a global platform. Through our multidisciplinary trade publication and journal, our mission is to amplify the voices of exceptional professionals and researchers, creating pathways for recognition and impact in an increasingly connected world.
Member
%20--%3e%3c!DOCTYPE%20svg%20PUBLIC%20'-//W3C//DTD%20SVG%201.1//EN'%20'http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd'%3e%3csvg%20version='1.1'%20id='Layer_1'%20xmlns='http://www.w3.org/2000/svg'%20xmlns:xlink='http://www.w3.org/1999/xlink'%20x='0px'%20y='0px'%20viewBox='0%200%20200%2067.9'%20style='enable-background:new%200%200%20200%2067.9;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill:%234F5858;}%20.st1{fill:%233EB1C8;}%20.st2{fill:%23D8D2C4;}%20.st3{fill:%23FFC72C;}%20.st4{fill:%23EF3340;}%20%3c/style%3e%3cg%3e%3cg%3e%3cg%3e%3cg%3e%3cpath%20class='st0'%20d='M76.1,37.5c-0.4-2.6-2.9-4.6-5.8-4.6c-5.2,0-7.2,4.4-7.2,9.1c0,4.4,2,8.9,7.2,8.9c3.6,0,5.6-2.4,6-5.9H82%20c-0.6,6.6-5.1,10.8-11.6,10.8c-8.2,0-13-6.1-13-13.7c0-7.9,4.8-14,13-14c5.8,0,10.7,3.4,11.4,9.5H76.1z'/%3e%3cpath%20class='st0'%20d='M84,35.9h5v3.6h0.1c1-2.4,3.6-4.1,6.1-4.1c0.4,0,0.8,0.1,1.1,0.2v4.9c-0.5-0.1-1.3-0.2-1.9-0.2%20c-3.9,0-5.2,2.8-5.2,6.1v8.6H84V35.9z'/%3e%3cpath%20class='st0'%20d='M106.4,35.4c6,0,9.9,4,9.9,10.1c0,6.1-3.9,10.1-9.9,10.1c-6,0-9.9-4-9.9-10.1%20C96.5,39.4,100.4,35.4,106.4,35.4z%20M106.4,51.6c3.6,0,4.7-3.1,4.7-6.1c0-3.1-1.1-6.1-4.7-6.1c-3.6,0-4.6,3.1-4.6,6.1%20C101.8,48.6,102.8,51.6,106.4,51.6z'/%3e%3cpath%20class='st0'%20d='M122.4,48.9c0,2.3,2,3.2,4,3.2c1.5,0,3.4-0.6,3.4-2.4c0-1.6-2.2-2.1-6-3c-3-0.7-6.1-1.7-6.1-5.1%20c0-4.9,4.2-6.1,8.3-6.1c4.2,0,8,1.4,8.4,6.1h-5c-0.1-2-1.7-2.6-3.6-2.6c-1.2,0-2.9,0.2-2.9,1.8c0,1.9,3,2.1,6,2.9%20c3.1,0.7,6.1,1.8,6.1,5.4c0,5-4.4,6.7-8.7,6.7c-4.4,0-8.8-1.7-9-6.7H122.4z'/%3e%3cpath%20class='st0'%20d='M141.6,48.9c0,2.3,2,3.2,4,3.2c1.5,0,3.4-0.6,3.4-2.4c0-1.6-2.2-2.1-6-3c-3-0.7-6.1-1.7-6.1-5.1%20c0-4.9,4.2-6.1,8.3-6.1c4.2,0,8,1.4,8.4,6.1h-5c-0.1-2-1.7-2.6-3.6-2.6c-1.2,0-2.9,0.2-2.9,1.8c0,1.9,3,2.1,6,2.9%20c3.1,0.7,6.1,1.8,6.1,5.4c0,5-4.4,6.7-8.7,6.7c-4.4,0-8.8-1.7-9-6.7H141.6z'/%3e%3cpath%20class='st0'%20d='M156.1,35.9h5v3.6h0.1c1-2.4,3.6-4.1,6.1-4.1c0.4,0,0.8,0.1,1.1,0.2v4.9c-0.5-0.1-1.3-0.2-1.9-0.2%20c-3.9,0-5.2,2.8-5.2,6.1v8.6h-5.3V35.9z'/%3e%3cpath%20class='st0'%20d='M174.2,46.8c0.1,3.3,1.8,4.9,4.7,4.9c2.1,0,3.8-1.3,4.1-2.5h4.6c-1.5,4.5-4.6,6.4-9,6.4%20c-6,0-9.8-4.1-9.8-10.1c0-5.7,4-10.1,9.8-10.1c6.5,0,9.7,5.5,9.3,11.4H174.2z%20M182.7,43.5c-0.5-2.7-1.6-4.1-4.2-4.1%20c-3.3,0-4.3,2.6-4.4,4.1H182.7z'/%3e%3cpath%20class='st0'%20d='M190.9,39.5h-3.1v-3.5h3.1v-1.5c0-3.4,2.1-5.8,6.4-5.8c0.9,0,1.9,0.1,2.8,0.1v3.9c-0.6-0.1-1.3-0.1-1.9-0.1%20c-1.4,0-2,0.6-2,2.2v1.1h3.6v3.5h-3.6v15.6h-5.3V39.5z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cpolygon%20class='st1'%20points='0,67.9%200,47.4%2016.8,41.9%2046.6,52.1%20'/%3e%3cpolygon%20class='st2'%20points='29.8,26.1%200,36.4%2016.8,41.9%2046.6,31.7%20'/%3e%3cpolygon%20class='st0'%20points='16.8,41.9%2046.6,31.7%2046.6,52.1%20'/%3e%3cpolygon%20class='st3'%20points='46.6,0.2%2046.6,20.6%2029.8,26.1%200,15.9%20'/%3e%3cpolygon%20class='st4'%20points='29.8,26.1%200,36.4%200,15.9%20'/%3e%3c/svg%3e)
Important Links
Contact Info
info@theedgereview.org
Address:
14781 Pomerado Rd #370, Poway, CA 92064